Accurate positioning of the sound source is the first step for the mobile device to perform auditory scene analysis. The result has a direct impact on the subsequent hybrid sound source separation, sound source identification and speech recognition. Delayed summing beamforming techniques have been widely used in sound source localization, requiring the use of signals to reach the Time Difference Of Arrival (TDOA) of different microphones in the microphone array. The Generalized Cross Correlation-Phase Transform (GCC-PHAT) algorithm has a short decision delay and good tracking ability. It is suitable for low reverberation environment and is a commonly used TDOA estimation algorithm.
VALIN JM proposes an improved GCC-PHAT algorithm that uses recursive methods to calculate weights, namely the continuous value-frequency-weighted GCC-PHAT algorithm to improve the robustness of the original algorithm to additive noise. Continuous weight calculation requires the Minimum Controlled Recursive Averaging (MCRA) algorithm to estimate the noise, but the MCRA algorithm needs to adapt to the time adjustment parameters after the noise changes. Therefore, for additive non-stationary or noise, continuous weights are used. The weighting method cannot eliminate its interference and eventually leads to TDOA estimation errors. Therefore, based on the frequency-weighted GCC-PHAT algorithm, this paper proposes a frequency-discrete weighted GCC-PHAT algorithm to eliminate wind noise and background noise by using the difference between the received signal's stroke noise and the frequency of the sound source signal. Interference with TDOA estimates. The experimental results show that compared with the original algorithm, the reliability and computational efficiency of the new algorithm are significantly improved.
1 cross-correlation algorithm to estimate signal time difference
1.1 Scene acoustic model
The sound source signal is propagated in a reverberant environment with additive noise and received by the microphone array. Additive noise consists of background noise and wind noise. Wind noise is a special kind of non-stationary noise generated by the turbulence of the surface of the microphone film, causing severe distortion of the received signal. Background noise approximates the diffuse noise generated by far-field sources in an acoustic environment. The sound source signal is not related to additive noise such as wind noise and background noise.
Let n be the signal time domain sampling number, m is the microphone number in the array, s(n) is the sound source signal, hm(n) is the room system impulse response sequence between the sound source and the microphone m, and wm(n) is the wind. Noise, bm(n) is the background noise signal. The background noise does not need to consider reverberation, then the microphone m receive signal ym(n) is expressed as:
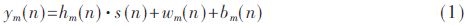
1.2 Frequency-weighted GCC-PHAT algorithm
The received signal is non-stationary over the entire time domain. The post-framing signal is transformed to the time-frequency domain analysis by the short-time Fourier transform using the short-time stationary characteristic of the received signal. The Haining window h(n) of length N is selected to frame the received signal to reduce the frequency truncation effect between the signals. Let the step length of the signal frame be ΔN sampling intervals, then the first frame of the received signal is represented as ym(lΔN+n), and the Fourier transform result is:

2 discrete value frequency point weighted GCC-PHAT algorithm
2.1 Discrete frequency weights
The frequency continuous weight calculation proposed by VALIN JM et al. is based on a priori signal-to-noise ratio (SNR) estimation. The continuous weight corresponding to the frequency point k is:

In the formula, 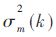
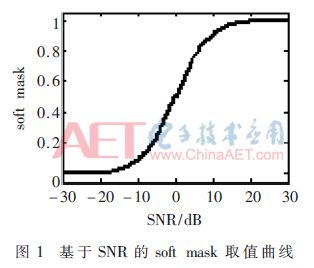
The continuous weight is a monotonic function about the signal-to-noise ratio. The value field is [0,1], which is represented by soft mask. The value is shown in Figure 1.
Frequency continuous weight calculation relies on noise power spectrum estimation and signal-to-noise continuity between adjacent frames. Comparing the wind noise and the instantaneous power of the speech signal with time, it can be seen that the wind-time variation of the wind noise is stronger than that of the speech signal [6]. The existing speech enhancement algorithms all have default noise changes slower than speech, so for signals containing wind noise, the above method cannot obtain a priori signal-to-noise ratio. And the continuous weight value is [0, 1]. When the sound source signal is seriously interfered by noise (SNR<0), the signal frequency corresponding weight is greater than zero, and the weighted signal still retains the noise component, resulting in the final TDOA estimation error. . Based on the existing frequency point weighting method, this paper proposes a wind noise suppression algorithm using frequency discrete weights. The new weight is a function of the coherence value of the signal frequency, does not depend on the noise estimation, and only takes the discrete values ​​0 and 1, completely eliminating the interference of the noisy frequency point on the TDOA estimation result. New weight 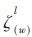
The wind noise is generated by the turbulence of the microphone surface, and the wind noise frequency between the different microphones is not coherent. However, for the same source signal, the received signal of the microphone in the array has high coherence at each frequency point. The Magnitude Squared Coherence (MSC) is introduced to quantify the coherence between the frequency points of the signal:
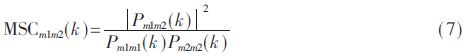
In the formula, Pm1m2, Pm1m1, and Pm2m2 are the mutual power spectral density and the self power spectral density of the signals of the microphones m1 and m2, respectively.
The MSC value reflects the degree of coherence of different signals at frequency k. As shown in FIG. 2, for the two signals of the near-field stationary sound source, the MSC value is near 1 in the frequency range of the signal existence, and the MSC value is always distributed near 0 in the low frequency region where the wind noise exists. Figure 3 shows the value of a 1-frame signal MSC containing wind noise. In the low frequency range where wind noise exists, 0 ≤ MSC ≤ 1 at each frequency point of the signal, and the more noise components are included, the smaller the value of MSC is. The signal MSC is close to 1 at the frequency outside the wind noise frequency range. However, the background noise also has coherence [7], and its MSC value satisfies the formula (8), where dm1m2 is the distance between the microphones. Therefore, it is necessary to eliminate the background noise before using the coherent difference to eliminate wind noise.

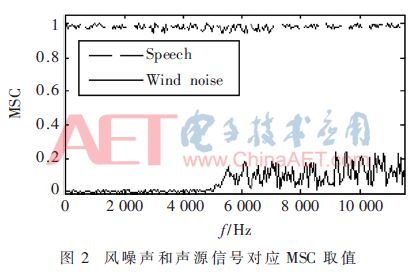
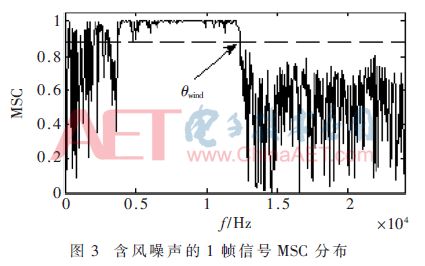
Analysis of different types of signal discovery, only the near-field stationary sound source signal with no noise interference, the MSC value between each frequency point is always close to 1. The remaining signal frequency points MSC take values ​​in [0, 1]. Therefore, the coherent value of the inter-signal frequency point can be used to detect the noise, and only the undisturbed frequency point in the signal is retained by the weighting method. The mathematical expression of the above conclusion is as shown in equation (9), where θwind is the coherence threshold.



Unlike the continuous frequency point weight calculation based on a single signal, the new weight calculation is based on two signals at the same time, then equation (3) can be expressed as:
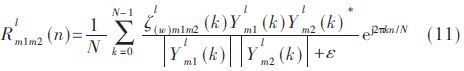
2.2 Pre-emphasis signal
The MCRA algorithm avoids the error estimation of the signal activity detection method caused by high false detection rate in low signal noise and silent segments. However, the MCRA algorithm searches for the minimum band power spectrum within a fixed length time window, resulting in a noise estimation lag. This paper proposes a current power spectrum minimum value search method in continuous time domain to improve the estimation speed. Before searching for the minimum power spectrum, first perform the following time domain recursive smoothing to obtain the smoothed power spectrum value:

Since the noise prior probability ratio is a monotonic function, according to the Bayes minimum risk cost decision criterion, the MCRA algorithm uses the ratio Sr(l,k) of the signal power spectrum to its local minimum to compare with the fixed threshold δ to determine whether the frequency point contains a signal component. Calculate the probability of signal existence. However, the fixed threshold δ is only suitable for stationary noise conditions and is insensitive to decisions involving non-stationary noise conditions. According to the signal frequency distribution characteristics: wind noise is distributed in the middle and low frequency regions, and the middle and high frequency parts are sound source signals containing background noise. The new algorithm selects the following segmentation threshold δ(k):

2.3 algorithm operation load analysis
The computing resources of mobile devices are limited, and the real-time performance of the algorithms is also required. Therefore, the amount of algorithm operations must be considered. For arrays containing M microphones, TDOA is estimated using a frequency-weighted GCC-PHAT algorithm, which requires M FFT and M(M-1)/2 IFFT operations per frame. In order to simplify the analysis, assuming that the Fourier positive and inverse transform operations are the same, the array of M microphones is estimated to be (M2+M)/2 operations, and the complexity is O(M2), so the array The number of microphones in the middle increases, and the amount of arithmetic operations increases rapidly.

3 analysis and comparison of experimental results
3.1 Experimental parameters
This section compares the performance of weighted GCC-PHAT algorithms with different frequency points under different test conditions. Table 1 gives the algorithm corresponding parameters. To ensure that all frequency components of the received signal are obtained after time-frequency conversion, set fs to 48 000 Hz; the number of sampling points per frame contained in the received signal is corresponding to the signal duration of 20 ms to 30 ms, and the window sequence is set to the same length; Continuity between frames, set frame step ΔN=N/2, that is, 50% overlap between frames; c is the sound speed under the condition of 20 °C, 101.1 kPa; ε is a fraction close to 0, to avoid the overflow of the result of formula (11) in practical application. The judgment thresholds θwind, θD, and θmin are determined based on the results of multiple experiments. According to the parameters in Table 1, the algorithm introduces a delay of Δl·ΔN/fs=32 ms. In human-computer voice interactions, this magnitude of time delay can be ignored.
Based on the IMAGE method [9], the impulse response sequence of a reverberant room model with a size of 10 m × 8 m × 3.5 m is calculated. Select a 7 s speech as the target sound source signal, and convolute the reverberation effect of the impulse analog signal. At present, there is no corpus to provide corresponding wind noise signals, which need to be collected through experiments. The signal acquisition uses a pair of matched omni-directional Beyerdynamic MM1 microphones, and the simulated airflow is generated by an air compressor. Establish a Cartesian coordinate system with the corner of the room as the coordinate origin. The sound source and microphone position are shown in Table 2. i, j, and k are x, y, and z axis unit vectors.
3.2 Algorithm performance indicators

3.3 Analysis of results
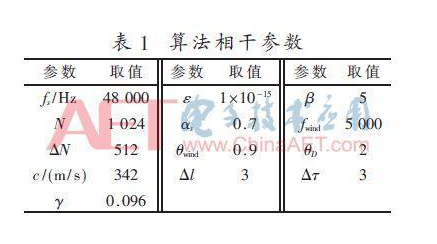
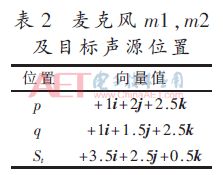
Figure 5 and Figure 6 are the spectral maps of the noisy (SNR=5 dB) signal in the reverberation environment (RT60=200 ms) and the weight distribution of the weighting methods of different frequency points. Figure 5(a) shows that wind noise is concentrated in the low frequency region of the signal and changes rapidly over time. The MCRA algorithm cannot accurately estimate the wind noise. Therefore, the continuous weight of the IF point in Fig. 5(b) is close to 1 in the low frequency region, and there is no attenuation on the wind noise frequency. The frequency of the noisy signal is taken into the correlation value. The noise power spectrum estimation curve in Fig. 6(a) shows that for stationary noise, the minimum attenuation of the signal power on the frequency band is close to the noise power value, so the algorithm based on the minimum statistics eliminates the effect of smooth background noise. However, for fast-changing noise, the algorithm design determines the estimated value to produce hysteresis, and the enhanced signal still contains wind noise. It also shows that the signal enhancement method can not eliminate wind noise interference. In this paper, the corresponding weight distribution of the algorithm is shown in Figure 6(b). The interference frequency (the weight is 0) in the low frequency range of the signal is judged and directly removed, and only the strong coherence frequency (weight value 1) is retained. The frequency of the signal in the middle and high frequency areas outside the wind noise frequency range is kept as much as possible, and the correlation value is calculated.
Figure 7 is a graph showing the statistics of TDOA results using the GCC-PHAT algorithm with different weights in the above experimental conditions. The experimental results show that the estimated statistical peaks of the GCC-PHAT algorithm without weighting and using continuous weights are all at Ï„c(Delay=-3), and the corresponding position sound source is the turbulence of the microphone surface. Only the GCC-PHAT algorithm weighted by the wind mask weight is distributed in the vicinity of Ï„t(Delay=-18), and the corresponding position is the target sound source, which satisfies the application requirements.
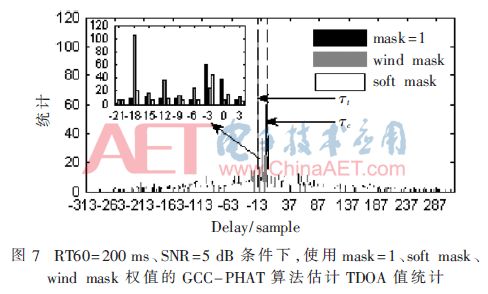
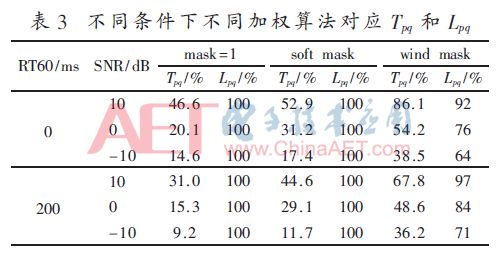
Table 3 compares the reliability (Tpq) and computational load (Lpq) of TDOA results with different frequency-weighted GCC-PHAT algorithms under different reverberation and SNR test conditions. In the actual scene, the special way of generating wind noise determines that it must interfere heavily with the signal. For example, in a low reverberation (RT60=0), low signal to noise (SNR=0 dB) environment, the wind mask weighting algorithm is used to estimate the result corresponding to Tpq=54.2%, which is better than using continuous weights (31.2%) and unweighted ( 20.1%) of the GCC-PHAT algorithm. In the low signal-to-noise environment with reverberation (RT60=200 ms, SNR=0 dB), the algorithm using wind mask weighting results in a drop of Tpq to 48.6%, which is still better than other weighting algorithms. Although the new weighting algorithm has an increased amount of computation in reverberation, it is significantly lower than other existing algorithms. Experiments show that in the scene with wind noise interference, the results obtained by the proposed algorithm are more reliable and the computational complexity is smaller.
4 Conclusion
Estimating the TDOA value into the beamforming algorithm by the GCC-PHAT algorithm is a common method for locating the sound source. In this paper, the reason why the existing GCC-PHAT algorithm can't eliminate the wind noise interference problem is analyzed. By studying the time-frequency characteristics of the target signal and the noise signal, a frequency-discrete weighted GCC-based frequency-frequency coherence difference is proposed. PHAT algorithm. Experiments show that compared with the continuous value frequency point weighting algorithm based on SNR estimation, the results obtained by the proposed method are accurate and reliable, and the computational complexity is small, which has certain engineering practical value.
Tempered Glass Screen Protector
The JJT Tempered Glass Screen Protective Film is protected by specially treated glass, and the Tempered Glass Screen Protector brings excellent scratch resistance to the screen. The Tempered Glass Protective Film is made of shockproof technology, which has the characteristics of anti-scratch, anti-fingerprint and anti-oil, which can greatly reduce the damage to the screen due to strong collision. The adhesive force of the silicon adhesive ensures that there is nothing between the screen protector and the screen, thereby improving touch sensitivity. Ultra-transparent glass can ensure a better clear image quality than ordinary Screen Protectors.
The surface hardness of the Tempered Glass Screen Protection Film is 9H, which is 4 times that of ordinary PET Film. Sharp objects (such as knives and keys) will not scratch the surface.
The Screen Protector has an "oleophobic and waterproof" coating to prevent fingerprints and other contaminants, making the screen protector easy to clean.
It has unparalleled touch and high responsiveness to touch, 99.9% transparency, transparent without bubbles.
Tempered Screen Protector, Tempered Glass Screen Protector, Tempered Glass Protective Film, Tempered Glass Film, Tempered Glass Screen Protective Film
Shenzhen Jianjiantong Technology Co., Ltd. , https://www.jjtbackskin.com