Editor's note: Today, DeepMind researchers published a paper on Science and launched a new neural network-GQN, which can reconstruct all three-dimensional scenes with only a few two-dimensional photos, which can be said to be another in the field of computer vision The key breakthrough.

Allowing machines to perceive the spatial environment seems to have always been the focus of DeepMind's research. We reported another study of theirs more than a month ago: DeepMind uses AI to decrypt the brain: what happens to the brain when you find your way. Spatial perception is simple for humans. For example, when we walk into a room for the first time, we can know what objects are in the room and where they are at a glance. By only seeing the three legs of the table, you can also infer the approximate position and shape of the fourth leg. In addition, even if you are not familiar with every corner of the house, you can outline its plan, or you can imagine what the room should look like from another angle.
But it is really difficult for artificial intelligence systems to do the above behaviors. The most advanced computer vision systems still need to be trained on large labeled data sets, and data labeling is a time-consuming and laborious task, so each model can only capture a small part of the scene. As the network becomes more and more complex, the surrounding environment you want to learn more about becomes more complicated: Where is the nearest seat? What is the material of the sofa? Where is the light source of all shadows? Where could the light switch be?
In this research, DeepMind researchers introduced a framework that can perceive the surrounding environment-GQN (Generative Query Network). Just like babies or animals, GQN collects data by observing the surrounding environment to learn, without the need for humans to mark the scene, to grasp the general spatial structure.
The GQN model consists of two parts: a presentation network and a generation network. The representation network takes the picture observed by the agent as input and generates a representation (vector) that describes the basic scene. After that, the generative network predicts (or "imagines") the scene from a perspective not previously observed.
However, the presentation network does not know from which perspective the generation network will predict the scene, so it must find an efficient and accurate way to describe the scene plane. It simply expresses it by capturing the most important elements, such as the location, color, and room plan of the object. During training, the generator learns to recognize objects, features, relationships, and the laws of the environment. This set of "sharing" concepts allows the presentation network to describe the scene in a highly concise and abstract way, and the remaining details are supplemented by the generation network. For example, the representation network uses a small string of numbers to represent a "blue square", and the generating network knows how to display it in pixels from a certain angle.
DeepMind researchers have done many experiments on GQN in the virtual 3D environment generated by the program, including a variety of different objects, which are placed in different positions, and the shapes, colors, and materials are different, and the light direction and The degree of occlusion. By training on these environments, they used GQN's representation network to generate a scene that they had never seen before. In the experiment, people found that GQN showed several important characteristics:
The GQN generation network can "imagine" scenes that have not been seen before from a new perspective, with very high accuracy. Given a scene representation and a new camera angle, the network does not need any previous information to generate accurate images. Therefore, the generative network can also be approximated as a renderer learned from data:
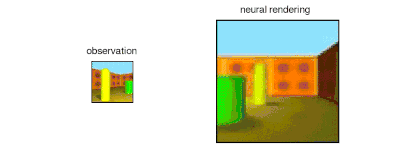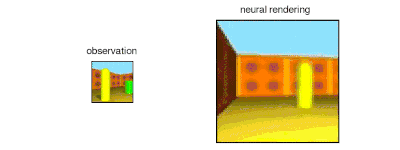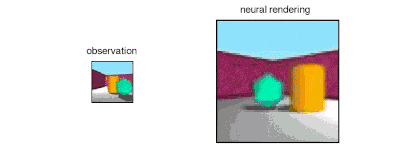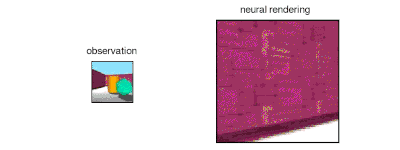
GQN's representation network can independently learn to count, locate, and classify objects. Even in small representations, GQN can make very accurate predictions from specific perspectives, almost exactly the same as reality. This shows that the network has been observed very carefully. For example, the following scene is stacked with several squares:
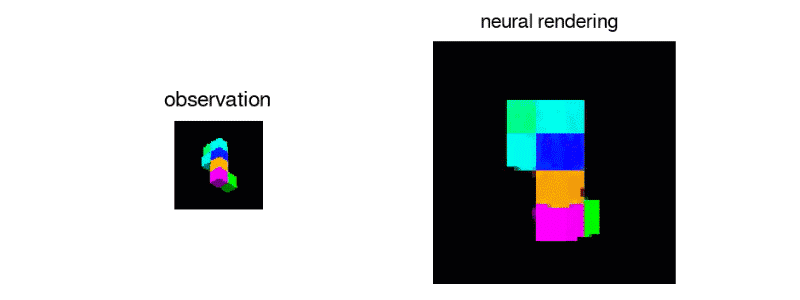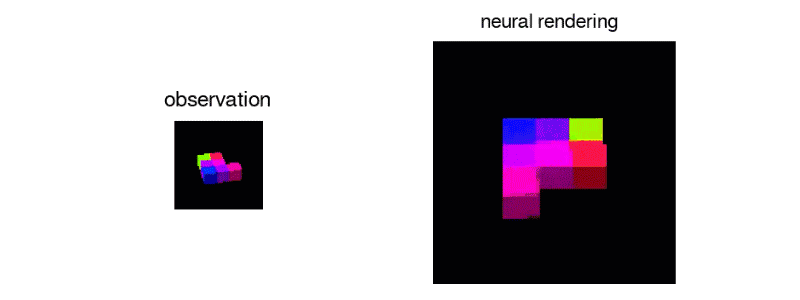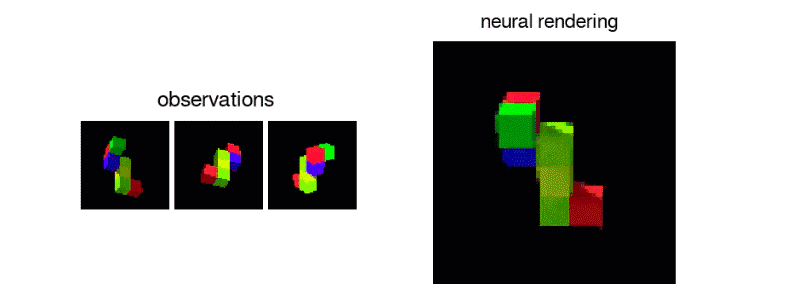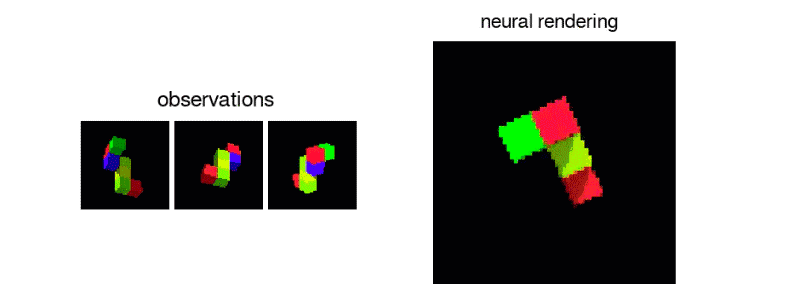
GQN can express, measure and reduce uncertainty. Even without seeing all the scenes completely, the network can explain the uncertainties. At the same time, a complete scene can be assembled according to some images. The following first-person perspective and top-down prediction methods are the "secrets". The model expresses uncertainty through its predicted variability, where the predicted variability decreases as it moves through the maze (the gray triangle is the observation position).
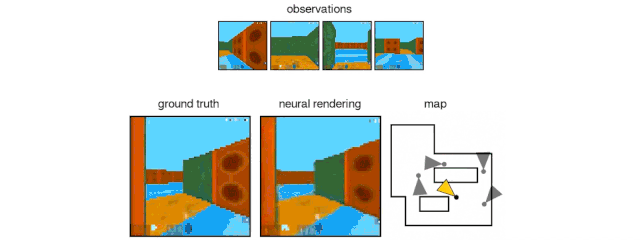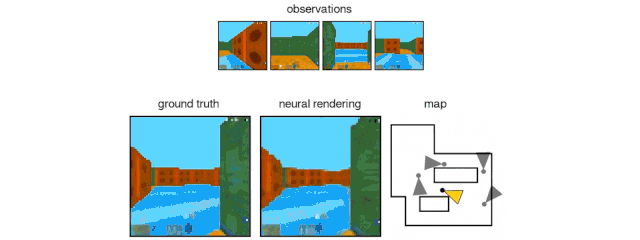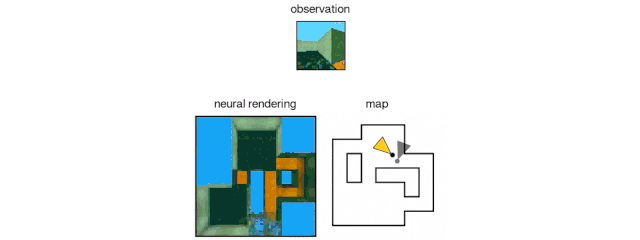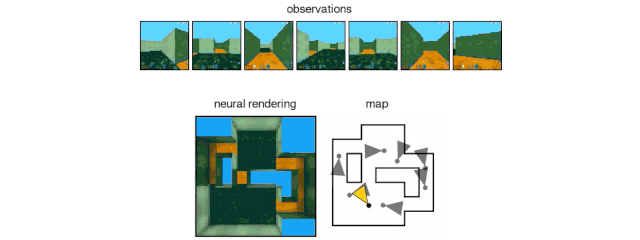
GQN stands for support for stable, data-efficient reinforcement learning. Given the GQN representation, the current top deep reinforcement learning agents begin to learn to complete tasks in a data-efficient manner. For these agents, the information compiled in the generative network can be regarded as the inherent cognition of the environment:
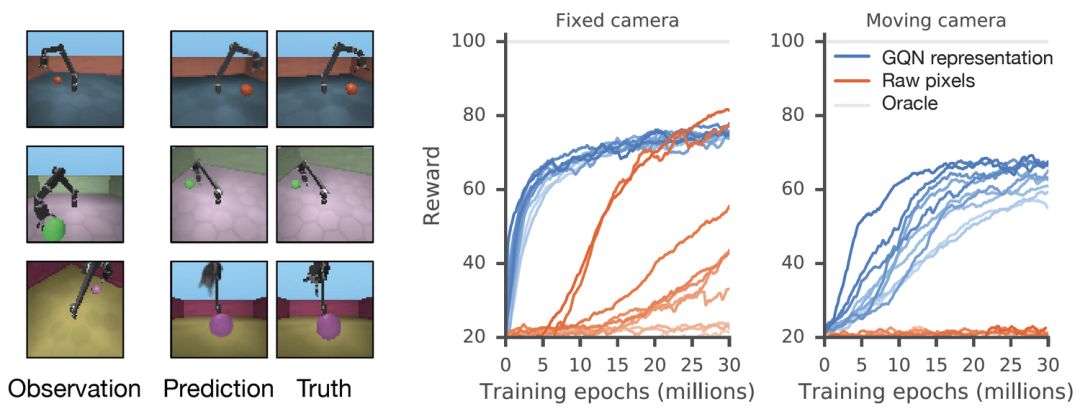
Using GQN, we have observed effective learning with more data, which is nearly 4 times faster than the usual method using only raw pixels to reach the level of convergence
Compared with previous studies, GQN is a new and simple way to learn real-world scenarios. Importantly, this method does not require modeling specific scenarios or spending a lot of time labeling content. One model can be applied to multiple scenarios. It also learned a powerful neural renderer that can generate accurate scene images at any angle.
However, compared with some traditional computer vision technologies, the method proposed this time still has many limitations, and is currently trained on virtual synthetic scenes. However, with the emergence of more available data and the improvement of hardware, researchers hope to further lasso the possibilities of GQN, such as applying it to real-world scenes, while improving imaging resolution. In the future, studying GQN is very important for broader scene understanding, such as adding the dimension of time, letting it learn the understanding of scenes and movement, and applying it to VR and AR technologies at the same time. Although the road ahead is long, this work is an important step for fully automatic scene recognition.
360° Ways Privacy Filter,360 Degree Anti Spy Privacy Screen,Anti Spy Privacy Screen,Privacy Screen Protectors
Guangdong magic Electronic Limited , https://www.magicmax.cc