HBase is a high-reliability, high-performance, column-oriented, scalable distributed storage system that uses HBase technology to build large-scale structured storage clusters on inexpensive PC Servers. The goal of HBase is to store and process large amounts of data, specifically to handle large amounts of data consisting of thousands of rows and columns using only common hardware configurations.
Different from MapReduce's offline batch computing framework, HBase is a randomly accessible storage and retrieval data platform, which makes up for the shortcomings of HDFS that cannot access data randomly. It is suitable for business scenarios where real-time requirements are not very high. HBase stores Byte arrays, which don't mind data types, allowing dynamic, flexible data models.
HBase features· Large: A table can have hundreds of millions of rows and millions of columns.
· Column-oriented: storage and permission control for lists (cluster), column (cluster) independent retrieval.
· Sparse: For NULL columns, storage space is not used, so tables can be designed to be very sparse.
No mode: Each row has a primary key that can be sorted and any number of columns. Columns can be dynamically added as needed. Different rows in the same table can have distinct columns.
· Multi-version of data: There can be multiple versions of data in each unit. By default, the version number is automatically assigned, and the version number is the timestamp when the cell is inserted.
· Single data type: The data in HBase is a string, no type.
HBase application scenarioHBase is not suitable for all scenarios.
First, be sure that there is enough data, and if there are hundreds of millions or hundreds of billions of rows of data, HBase is a good alternative. If you have only a few thousand or millions of rows, then a traditional R DBMS might be a better choice. Because all data can be saved in one or two nodes, other nodes in the cluster may be idle.
Second, be sure to not rely on the extra features of all RDBMSs (for example, column data types, second indexes, transactions, advanced query languages, etc.).
Third, make sure you have enough hardware. Because HDFS is less than 5 data nodes, it basically does not show its advantages.
Although HBase works fine on a single laptop, it should only be considered a development phase configuration.
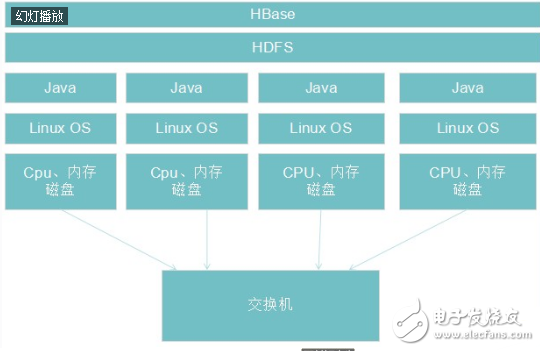
Second, HBase architecture 2.1 Design ideasHBase is a distributed database that uses ZooKeeper to manage clusters and HDFS as the underlying storage. At the architectural level, it consists of HMaster (Leader elected by Zookeeper) and multiple HRegionServers. The basic architecture is shown in the following figure:
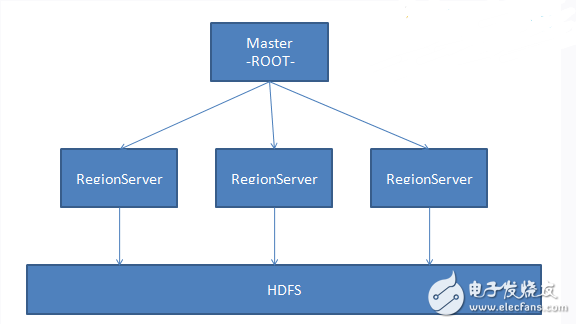
In the concept of HBase, HRegionServer corresponds to one node in the cluster, one HRegionServer is responsible for managing multiple HRegions, and one HRegion represents a part of the data of a table. In HBase, a table may require a lot of HRegions to store data, and the data in each HRegion is not disorganized. When HBase manages HRegion, it will define a range of Rowkey for each HRegion. The data falling within a certain range will be handed over to a specific Region, thus distributing the load to multiple nodes, thus taking advantage of the advantages of distributed and characteristic. In addition, HBase will automatically adjust the location of the Region. If a HRegionServer is overheated, that is, a large number of requests fall on the HRegion managed by the HRegionServer, HBase will move the HRegion to other nodes that are relatively idle, ensuring that the cluster environment is fully utilized. .
2.2 Basic ArchitectureHBase consists of HMaster and HRegionServer, and also follows the master-slave server architecture. HBase divides the logical table into multiple data blocks, HRegion, which are stored in HRegionServer. HMaster is responsible for managing all HRegionServers. It does not store any data itself, but only stores the mappings (metadata) of data to HRegionServer. All nodes in the cluster are coordinated by Zookeeper and handle various issues that may be encountered during HBase operation.
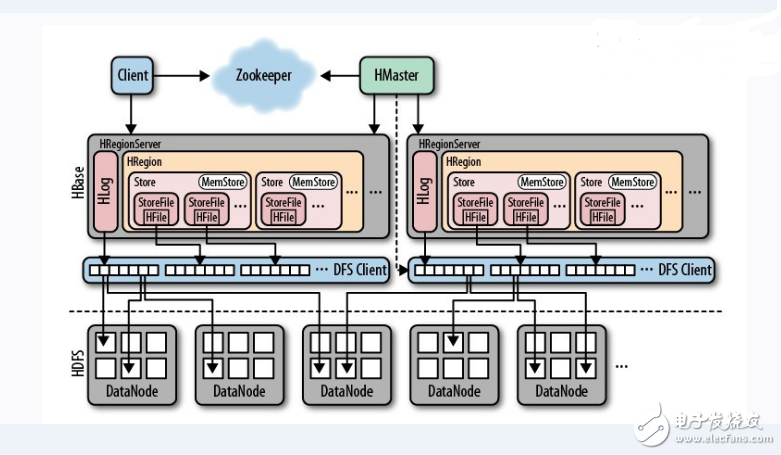
HBase is a distributed database similar to BigTable. It is a sparse long-term storage (on HDFS), multi-dimensional, and sorted mapping tables. The index of this table is the row keyword, column keyword, and timestamp. HBase data is a string, no type.
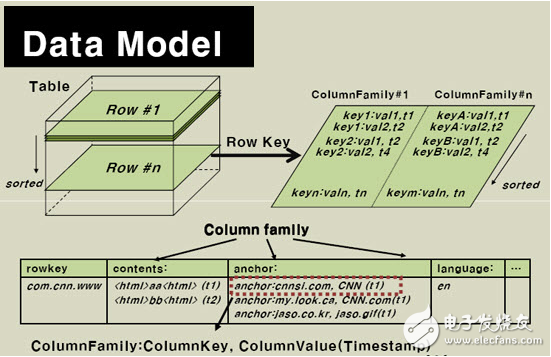
Think of a table as a large mapping. You can locate specific data by row key, row key + timestamp or row key + column (column family: column modifier). Since HBase is sparsely storing data, some columns can be blank. The above table gives the logical storage logical view of the com.cnn.www website. There is only one row of data in the table. The unique identifier of the row is “com.cnn.wwwâ€, and there is a time for each logical modification of this row of data. The stamp association corresponds. There are four columns in the table: contents: html, anchor:cnnsi.com, anchor:my.look.ca, mime:type, and each column gives the column family to which it belongs.
The RowKey is a unique identifier for the row of data in the table and serves as the primary key for retrieving records. There are only three ways to access rows in a table in HBase: access via a row key, range access for a given row key, and full table scan. The row key can be any string (maximum length 64KB) and stored in lexicographical order. For rows that are often read together, the key values ​​need to be carefully designed so that they can be stored together.
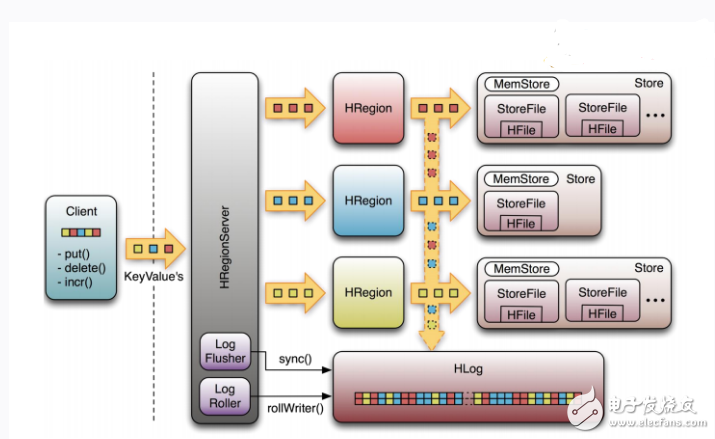
The figure below is the HRegionServer data storage relationship diagram. As mentioned above, HBase uses MemStore and StoreFile to store updates to the table. The data is first written to HLog and MemStore when it is updated. The data in the MemStore is sorted. When the MemStore accumulates to a certain threshold, a new MemStore is created, and the old MemStore is added to the Flush queue, and a separate thread is flushed to the disk to become a StoreFile. At the same time, the system will record a CheckPoint in Zookeeper, indicating that the data changes before this time have been persisted. When an unexpected system occurs, data in the MemStore may be lost. In this case, HLog is used to recover the data after CheckPoint.
StoreFile is read-only and cannot be modified once created. Therefore, the update of Hbase is actually an operation that is constantly added. When the StoreFile in a store reaches a certain threshold, a merge operation is performed, and the modifications of the same key are merged together to form a large StoreFile. When the size of the StoreFile reaches a certain threshold, the StoreFile is split and divided into two StoreFiles.
Step 1: The client sends a write data request to the HRegionServer through the scheduling of the Zookeeper, and writes the data in the HRegion.
Step 2: The data is written to the MemStore of HRegion until the MemStore reaches the preset threshold.
Step 3: The data in MemStore is Flushed into a StoreFile.
Step 4: As the number of StoreFile files increases, when the number of the StoreFile files increases to a certain threshold, the Compact merge operation is triggered, and multiple StoreFiles are merged into one StoreFile, and version merge and data deletion are performed at the same time.
Step 5: StoreFiles gradually forms an increasingly larger StoreFile through constant Compact integration operations.
Step 6: After the size of a single StoreFile exceeds a certain threshold, the Split operation is triggered to split the current HRegion into 2 new HRegions. The parent HRegion will go offline, and the two sub-HRegions from the new Split will be assigned to the corresponding HRegionServer by HMaster, so that the pressure of the original HRegion can be shunted to the two HRegions.
Read operation flowStep 1: The client accesses Zookeeper, finds the -ROOT-table, and obtains the .META. table information.
Step 2: Search from the .META. table, obtain the HRegion information of the target data, and find the corresponding HRegionServer.
Step 3: Obtain the data you need to find through HRegionServer.
Step 4: The memory of HRegionserver is divided into two parts: MemStore and BlockCache. MemStore is mainly used to write data, and BlockCache is mainly used to read data. Read the request first to the MemStore to check the data, check the BlockCache check, and then check the StoreFile, and put the read result into the BlockCache.
How hbase worksClient
First, when a request is generated, the HBase Client uses the RPC (Remote Procedure Call) mechanism to communicate with the HMaster and HRegionServer. For management operations, the Client performs RPC with the HMaster. For data read and write operations, the Client performs RPC with the HRegionServer.
Zookeeper
HBase Client uses RPC (Remote Procedure Call) mechanism to communicate with HMaster and HRegionServer, but how to address it? Since Zookeeper stores the address of the -ROOT-table and the address of the HMaster, it needs to be addressed to Zookeeper first.
HRegionServer will also register itself in Zookeeper in Ephemeral mode, so that HMaster can sense the health status of each HRegionServer at any time. In addition, Zookeeper also avoids a single point of failure for HMaster.
HMaster
When the user needs to manage the Table and Region, he needs to communicate with HMaster. Multiple HMasters can be started in HBase, and there is always a Master running through Zookeeper's Master EleTIon mechanism.
· Manage users to add, delete, and modify Tables
· Manage the load balancing of HRegionServer and adjust the distribution of the Region
· Responsible for the distribution of the new Region after Region Split
· Responsible for the Regions migration on the failed HRegionServer after the HRegionServer is down
HRegionServer
When the user needs to read and write data, you need to access HRegionServer. When HRegionServer accesses a subtable, it creates an HRegion object, and then creates a Store instance for each column family of the table. Each store will have a MemStore and 0 or more StoreFiles corresponding to it, and each StoreFile will correspond. An HFile, HFile is the actual storage file. Therefore, how many stores are there in a HRegion? An HRegionServer will have multiple HRegions and one HLog.
When the HStore storage is the core of HBase, it consists of two parts: MemStore and StoreFiles. MemStore is a Sorted Memory Buffer, user
The write data will first be placed in the MemStore. When the MemStore is full, it will be Flush into a StoreFile (the HFile is actually stored on the HDHS). When the number of StoreFile files increases to a certain threshold, the Compact merge operation will be triggered. The StoreFiles are merged into one StoreFile, and the merge process and data deletion will be performed during the merge process. Therefore, it can be seen that HBase actually only adds data, and all update and delete operations are performed in the subsequent compact process, which makes the user read. Write operations can be returned as soon as they enter the memory, ensuring the high performance of HBase I/O.
Let's take a look at the HBase workflow with a specific data Put process.
HBase Put process
The following is a timing diagram of the put process:
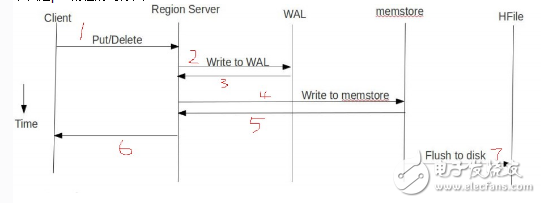
Client:
· The client initiates a Put write request, and the put writes the writeBuffer. If it is a batch commit, it is automatically submitted after the full cache is written.
· According to rowkey, put command to different regionserver
Server:
· RegionServer will put put by rowkey to different regions
· Region first writes data to wal
· After wal is successfully written, write data to memstore
· After the Memstore is written, check if the memstore size reaches the flush threshold.
· If the flush threshold is reached, write the memstore to HDFS to generate the HFile file.
HBase Compact &&Split
When the number of StoreFile files increases to a certain threshold, the Compact merge operation will be triggered, and multiple StoreFiles will be merged into one StoreFile. When the StoreFile size exceeds a certain threshold, the Split operation will be triggered and the current Region will be split into 2 Region, this is the old Region will be offline, the two Regions out of the new Split will be assigned to the corresponding HregionServer by HMaster, so that the pressure of the original Region can be spread to 2 Regions.
The following four Storefile files (obtained from the memstore file after flushing, the default 64M storefile) are merged into a large 256M storefile by Compact. When the Region threshold is set to 128M, Split will be two 128M. The Storefile, then HMaster then allocates the two storefiles to the Regionserver.
HFile
All data files in HBase are stored on Hadoop HDFS, mainly including two file types:
· Hfile: The storage format of KeyValue data in HBase. HFile is the binary format file of Hadoop. In fact, StoreFile is a lightweight package for Hfile, that is, the bottom of StoreFile is HFile.
· HLog File: WAL (write ahead log) storage format in HBase, physically Hadoop's Sequence File
The storage format of HFile is as follows:
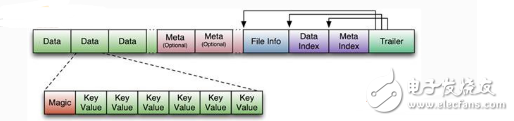
HFile files are not fixed in length, only two of them are fixed in length: Trailer and FileInfo.
There are pointers to the starting point of other data blocks in Trailer, and FileInfo records some meta information of the file. Data Block is the basic unit of hbase io. In order to improve efficiency, HRegionServer has LRU-based block cache mechanism.
The size of each Data block can be specified by parameters when creating a Table (the default block size is 64KB). The large Block is good for sequential Scan, and the small Block is good for random queries.
In addition to the first Magic, each Data block is a combination of KeyValue pairs. The Magic content is a random number, which is designed to prevent data corruption. The structure is as follows.
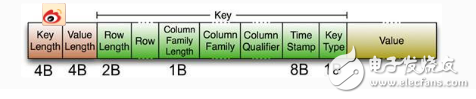
As shown in the figure above, the beginning is two fixed-length values, which indicate the length of the key and the length of the aleu. This is followed by Key, starting with a fixed-length value representing the length of the RowKey, followed by the RowKey, followed by a fixed-length value representing the length of the Family, then Family, followed by Qualifier, then two fixed-length values. , indicating TIme Stamp and Key Type (Put/Delete). The Value part is not so complicated, it is pure binary data.
HBase's three-dimensional ordered (ie lexicographical) storage
Hfile is the storage format of KeyValue data in HBase. As can be seen from the above HBase physical data model, HBase is a list-oriented (cluster) storage. Each Cell is uniquely identified by {row key,column(=“family + labelâ€), version}, and they are combined into a KeyValue. According to the above description, the key in this KeyValue is {row key, column(= "family" + "label"), version}, and value is the value in the cell.
The three-dimensional ordered storage in HBase refers to three-dimensional ordered storage consisting of rowkey (row primary key), column key (columnFamily+ "label"), and TImestamp (timestamp or version number).
Rowkey
Rowkey is the primary key of the row, which is sorted in lexicographic order. So the design of rowkey is crucial, related to the query efficiency of your application layer. When we query according to the rowkey range, we generally know startRowkey. If we only pass startRowKey through the scan: d starts, then all the queries that are larger than d are checked, and we only need the data starting with d, then It is necessary to limit by endRowKey. We can set the endRowKey to start with :d, and the latter is set according to your rowkey combination, which is usually one bit larger than the startKey.
· column key
The column key is the second dimension. After the data is sorted by the rowkey dictionary, if the rowkey is the same, it is sorted according to the column key, and is also sorted by dictionary.
We must learn to take advantage of this when designing a table. Like our inbox. We sometimes need to sort by topic, then we can set the theme to our column key, which is designed as a columnFamily+ theme. , such a design.
· TImestamp
The timestamp timestamp is the third dimension, which is sorted in descending order, that is, the latest data is ranked first. There is nothing to say about this. Other blogs on the Internet also mentioned more.
HLog Replay
According to the above description, we have already understood the basic principles of HStore, but we must also understand the function of HLog, because the above HStore is no problem under the premise of normal operation of the system, but in a distributed system environment, Unable to avoid system error or downtime, because once HRegionServer unexpectedly quits, the memory data in MemStore will be lost, which requires the introduction of HLog. Each HRegionServer has an HLog object. HLog is a class that implements Write Ahead Log. Each time a user operation writes to MemStore, it also writes a data to the HLog file. The HLog file is regular (when the file is persistent) The data into the StoreFile will roll out the new one and delete the old file. When the HRegionServer is terminated unexpectedly, the HMaster will be aware by the Zookeeper. The HMaster will first process the legacy Hlog files, split the Log data of different Regions, place them in the corresponding Region, and then redistribute the invalid Regions. In the process of loading the Region's Regionserver, the historical HLog needs to be processed. Therefore, the data in the Replay HLog is sent to the MemStore, and then flushed to the StoreFiles to complete the data recovery.
HLog storage format
WAL (Write Ahead Log): The process used by RegionServer to record the contents of the operation during the process of inserting and deleting. Only when the log is successfully written, the client is notified that the operation is successful.
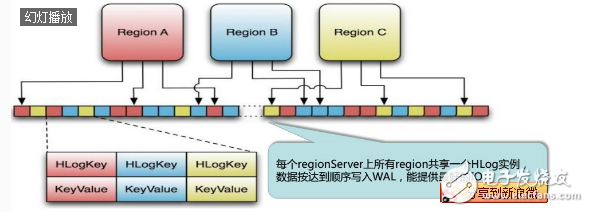
The figure above shows the structure of the HLog file. In fact, the HLog file is an ordinary Hadoop Sequence File. The Key of the Sequence File is the HLogKey object. The HLogKey records the attribution information of the written data. In addition to the table and Region names, it also includes the sequence. Number and timestamp, timestamp is the "write time", the starting value of the sequence number is 0, or the sequence number that was last stored in the file system.
The Value of the HLog Sequence File is the KeyValue object of HBase, which corresponds to the KeyValue in the HFile.
HBase performance and optimization factors affecting HBase performance
Power Storage LiFePO4 Battery Solar Energy Systems For Home
|
S/N
|
Item
|
Content
|
|
1
|
product type
|
Modular 48V large-capacity energy storage power system
|
|
2
|
Module model
|
48V200Ah
|
|
3
|
Weight
|
430kg
|
|
4
|
System capacity
|
200Ah*Parallel number(200~2000Ah)
|
|
5
|
Module dimension
|
19-inch standard cabinet width, thickness 5U, depth 480
|
|
6
|
Maximum continuous charge and discharge current
|
0.75C
|
|
7
|
Installation method
|
Pedal models, seat bucket models, etc.
|
|
8
|
IP rating
|
Module IP20, system power box can be customized IP65
|
|
9
|
Service life
|
10 years or 3000 cycles
|
|
10
|
Operating temperature range
|
Temperature: -20~60℃ Humidity: ≤85%RH
|
|
11
|
product description
|
The product is positioned as an energy storage power supply system, in accordance with the ultra-long storage/cycle life, modular design, can be connected in parallel according to the required system capacity, and can realize battery intelligent monitoring and
battery management through RS485 communication or CAN communication, and inverter power supply/ UPS power supply and other equipment are perfectly compatible and can be widely used in various 48V energy storage power systems |
|
14
|
certificate
|
MSDS,ISO9001,CB,UN38.3
|
Energy Storage Lithium Battery Cbinet For Home
Jiangsu Zhitai New Energy Technology Co.,Ltd , https://www.zt-tek.com