For different resources, virtualization mainly includes three aspects: computing virtualization, storage virtualization, and network virtualization. Next, we will introduce the virtualization methods and technologies of these three types of resources in detail. Today's main talk about virtualization in the "virtualization", that is, the main focus on CPU virtualization.

Compute virtualization usually includes three aspects of content
(1) CPU virtualization: Since multiple VMs share CPU resources, sensitive commands in the VM need to be intercepted and simulated.
(2) Memory virtualization: Because multiple VMs share the same physical memory, they need to be isolated from each other
(3) I/O virtualization: Since multiple VMs share a single physical device, such as a disk or network card, the idea of ​​using TDMA is generally used to multiplex through time-division multiplexing.
Introduction to CPU virtualization
For X86 processors, CPU virtualization is based on the fact that there are four different priorities for protection mode, from Ring 0 to Ring 3 respectively. The priority of these Rings varies with the function they perform. Among them, Ring 0 is used for operating system kernel and driver. It has the highest priority and has the highest “privilegeâ€. Ring 1 and Ring 2 are used for operating system services, followed by priority, Ring 3 is used for applications, and has the lowest priority. General applications are on the Ring 3 level, and Ring 1 and 2 are rarely used. For the commands issued by the application and the OS, the CPU always takes Direct ExecuTIon, as shown in the following figure:
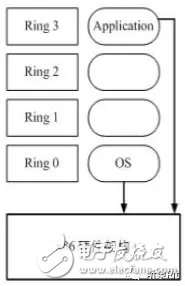
If you want to virtualize, Ring 0 this layer must be handed over to the VMM to handle the allocation of hardware resources.
Then the problem arises, because the OS must access the Ring 0 directly to control the hardware, and now the part of the Ring 0 has been handed over to VMM, the operating system is reduced to Ring 1, but because the X86 CPU is initially positioned as a single user At the time, the issue of allocating computing resources to different OSs was not considered; and the X86 instruction set architecture (ISA) is an abstract description of the processor, the design specification, defining what the processor can do. Its essence is a series of The instruction set synthesis.The current mainstream ISA has X86, ARM, MIPS, Power, etc. Here we only talk about the X86 ISA) 19 sensitive instructions are not privileged instructions, these instructions must be in Ring 0 this level can be used, otherwise operation The system will generate a warning, terminate the application, and even cause the system to crash.
Thus, after research, our siege lions proposed the following three methods to solve this problem.
(1) Full Virtualizaion
This method was originally proposed by VMware in 1999. It is a technique called binary translation (Binary TransLaTIon). The principle is to pre-block the non-virtualizable instrucTIons (nonvirtualizable instrucTIons) of these OSs through the VMM. Performing a binary translation replacement operation makes the operating system think that it can directly control the hardware and does not know that it has actually been virtualized into a virtual machine. As shown below:
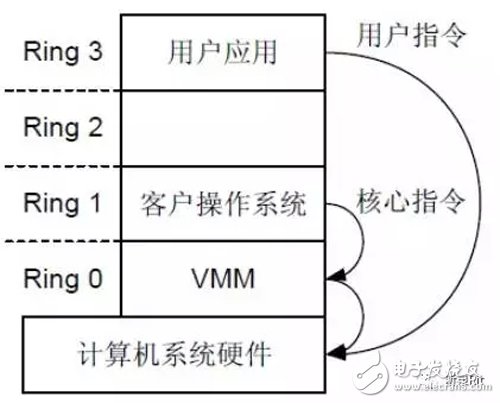
The general command of the application is still directly to the hardware request to maintain good performance.
The advantage of full virtualization is that the OS can be used directly without any modification. Moreover, the supported OS types are also the most, but without hardware assisted (Hardware Assisted Virtualization), the realization of full virtualization is very difficult.
(2) Paravirization
The principle of paravirtualization is to modify part of the code in the Guest OS core and implant a Hypercall so that Guest OS will convert the operations related to the privileged instructions into Hypercall to VMM (Vircall). Continue processing. The two optimization methods of batch and asynchronous supported by Hypercall make it possible to obtain the speed similar to the physical machine through Hypercall.
In this way, nonvirtualizable instructions that cannot be virtualized can be directly requested to the hardware through the HyperCall interfaces. The Guest OS part is still in Ring 0, and it is not required to be reduced to Ring 1. As shown below:
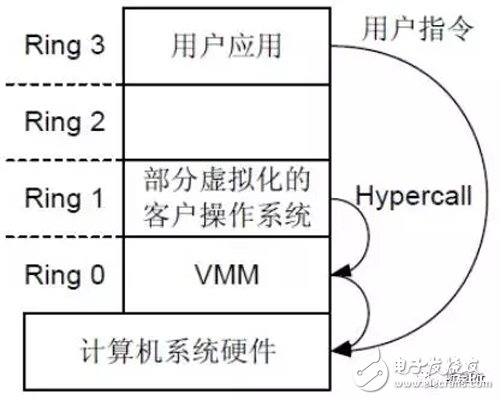
The advantage of paravirtualization is that the CPU and I/O losses are minimized. In theory, performance outperforms full virtualization technology. The disadvantage is that the OS kernel must be modified. Only a few Linux versions, such as SuSE and Ubuntu, support it. OS compatibility It is not good because Microsoft is not willing to modify its own operating system kernel, so if it is a Windows system, it cannot use paravirtualization.
VMware released Transparent Paravirtualization in 2005. For para-virtualized OS, you can open the para-virtualization through VMI (Virtual Machine Interface) on VMware's platform to increase I/O performance and reduce CPU usage. .
The principle is to open a backdoor by VMware tools on the guest OS that supports paravirtualization, communicate with the VMM, and then install a para-virtualized optimized driver on the OS to improve I/O performance and reduce CPU usage. This is the best way to support paravirtualized OS on VMware platform, but it must be noted that the underlying CPU Virtualization is still Full Virtualization using Binary Translation instead of Paravirtualization technology.
(3) CPU Hardware Assisted Virtualization
After 2005, virtualization gradually became a trend that was unstoppable. Intel and AMD decided to start with the fundamental architecture of the CPU, change the original privilege level Ring 0, 1, 2, 3, classified it as Non-Root mode, and added a Root Mode privilege level (someone called Ring -1 ), this way, the OS can be in the original Ring 0 level, and the VMM is adjusted to the lower level Root Mode level. As shown below:
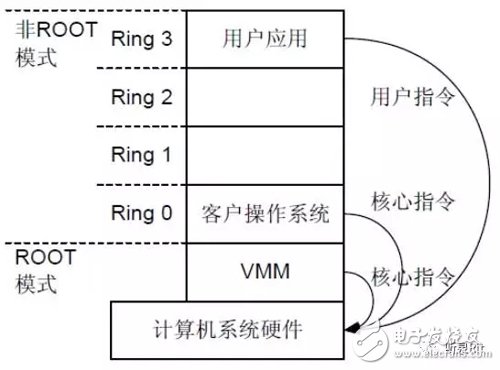
At present, there are two technologies: Intel's VT-x and AMD's AMD-V. The core idea is to introduce VMM and Guest OS in different modes (ROOT mode and non-ROOT mode) by introducing new instructions and operating modes, and Guest OS runs under Ring 0. Under normal circumstances, Guest OS core instructions can be directly executed under computer system hardware without going through VMM. When Guest OS executes a special instruction, the system will switch to VMM and let VMM process special instructions.
Hardware-assisted virtualization extends the topic
In hardware-assisted virtualization, the instruction set of the virtual machine runs directly on the physical CPU of the host. When the instructions in the virtual machine are designed for I/O operation or some special instructions, control is transferred to the host (here, in fact, Is assigned to the VMM), which is a process whose manifestation on the host is also a user-level process.
The following figure uses the KVM as an example.
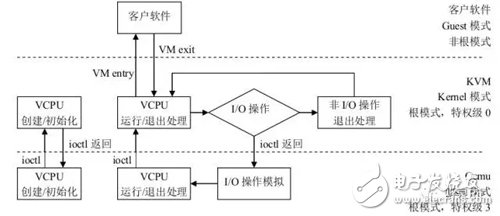
From the above figure, you can intuitively see that after the VMM completes the initialization of the vCPU and memory, the interface of the KVM is invoked through the ioctl to complete the creation of the virtual machine and create a thread to run the VM. Since the VM is set in the initial initialization Registers to help KVM find the entry for the instruction that needs to be loaded (main function). Therefore, after the thread invokes the KVM interface, the control of the physical CPU is passed to the VM. The VM runs in VMX non-root mode, which is a special CPU execution mode provided by Intel's VT-x. Then when the VM executes a special instruction, the CPU saves the context of the current VM to the VMCS register (this register is a pointer and saves the actual context address), and then the execution right is switched to VMM. The VMM gets the VM return reason and does the processing. If it is an I/O request, the VMM can directly read the VM's memory and simulate the I/O operation. Then it calls the VMRESUME instruction and the VM continues to execute. At this time, the VM executes the instruction of the I/O operation to be executed by the CPU. Now.
Below we only talk about some key concepts of VT-x.
(1) Two modes
VT-x adds two modes of operation for the IA 32 processor: VMX root operation and VMX non-root operation.
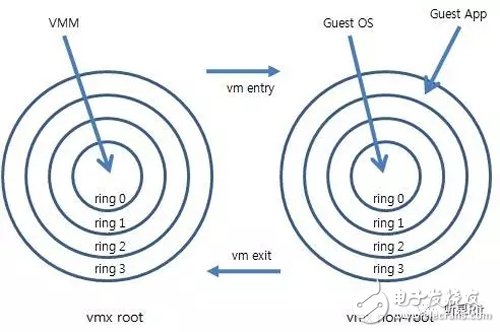
The VMM itself runs in the VMX root operation mode, and the VMX non-root operation mode is used by the Guest OS. Both operating modes support the four privilege levels, Ring 0 ~ Ring 3, so both VMM and Guest OS are free to choose their desired run level.
(2) mode conversion VM entry, running Guest OS
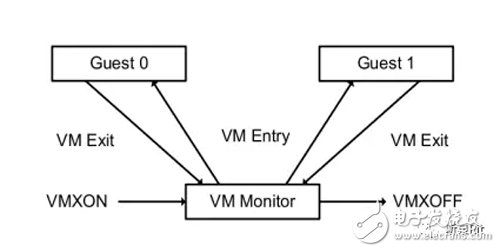
The two modes of operation can be interchanged. The VMM running in the VMX root operation mode switches to the VMX non-root operation mode by explicitly calling the VMLAUNCH or VMRESUME instruction. The hardware automatically loads the guest OS context and the guest OS gets the operation. This conversion is called the VM entry.
(3) mode conversion VM exit, running VMM
When Guest OS encounters an event that requires VMM processing, such as an external interrupt or page fault exception, or when the VMCALL instruction is invoked to invoke the VMM service (similar to the system call), the hardware automatically suspends Guest OS and switches to VMX root. Operation mode to resume the operation of VMM. This conversion is called VM exit.
In the VMX root operation mode, the behavior of the software is basically the same as that on a processor without VT-x technology; and the VMX non-root operation mode is very different. The main difference is that some instructions are executed at this time or VM exit occurs when certain events are encountered.
(4) Life cycle of VMM
VMM starts with the VMXON instruction and ends with the VMXOFF instruction.
The Guest is started for the first time and the Guest is loaded with the VMLAUNCH command. At this time, everything is new, such as the initial rip register. Subsequent Guest exit and then entry are through the VMRESUME instruction, which loads the contents of the VMCS (described later) to the current Guest's context so that the Guest can continue execution.
(5) Virtual Machine Control Block (VMCS)
VMCS is a 64-bit pointer to a real memory address. VMCS is a unit of vCPU, that is, how many vCPUs there are currently, how many VMCS pointers there are.
The VMM and Guest OS share the underlying processor resources, so the hardware needs a physical memory area to automatically save or restore the context of each other's execution. This area is called a virtual machine control block (VMCS) and includes a guest state area, a host state area, and an execution control area.
On VM entry, the hardware automatically loads the Guest OS context from the client status area. You do not need to save the context of the VMM. The reason is similar to that of the interrupt handler because the VMM will not be disturbed by the Guest OS if it starts running. Only when the VMM processes the work completely can it switch itself to the Guest OS. The next run of the VMM must be to handle a new event, so every time the VMM entry is started, the VMM starts from a generic event handler.
When the VM exits, the hardware automatically saves the Guest OS context in the client state area, loads the VMM's generic event handler address from the host state area, and VMM begins execution. The execution control area stores the flags that can manipulate the VM entry and exit, such as marking which events can cause the VM exit, and which kind of interrupts the VM entry will automatically “plug†into the Guest OS.
(6) Client status area and host status area in VMCS
Both the client status area and the host status area should contain some physical register information, such as the control registers CR0, CR3, CR4; ESP (ESP register stores the top of the stack after the call to function fun(). It always points to At the top of the stack, there is also an EBP register that stores the stack bottom pointer of the stack, which is usually called the stack base address. This is the beginning of the fun() function call, passed by ESP to EBP, and EIP (stored in the EIP register). The address of the next instruction to be executed by the CPU (RSP, RIP if the processor supports 64-bit extensions); CS, SS, DS, ES, FS, GS, and other segment registers and their descriptions; TR, GDTR , IDTR registers; MSR registers such as IA32_SYSENTER_CS, IA32_SYSENTER_ESP, IA32_SYSENTER_EIP and IA32_PERF_GLOBAL_CTRL.
The client status area does not include the contents of general registers, and the VMM decides whether to save them when the VM exits, improving system performance. The client status area also contains the contents of non-physical registers. For example, a 32-bit Active State value indicates the active state of the processor when the Guest OS executes. If the normal execution instruction is in the active state, if a triple fault is triggered (Triple Fault) ) or other serious errors are in the Shutdown state, and so on.
As mentioned earlier, the execution control area is used to store flags that can manipulate VM entry and VM exit, including:
External-interrupt exiting: used to set whether the external interrupt can trigger the VM exit regardless of whether the Guest OS masks the interrupt.
(7) Interrupt-window exiting:
If set, the VM exit is triggered when the Guest OS unmasks the interrupt.
(8) Use TPR shadow:
When using the CR8 to access the Task Priority Register (TPR task priority register), use the shadow TPR in VMCS to avoid triggering VM exit. At the same time, there is a TPR threshold setting in the execution control zone. VM exit is triggered only when the value of TR set in Guest OS is less than the threshold.
(9) CR masks and shadows:
Each bit of each control register has a corresponding mask to control whether Guest OS can directly write the corresponding bit or trigger VM exit. At the same time, the shadow control register is included in VMCS. When Guest OS reads the control register, hardware returns the value of shadow control register to Guest OS.
(10) bitmap bitmap:
VMCS also includes a set of bitmaps to provide better adaptability:
Exception bitmap: Select which exceptions can trigger the VM exit,
I/O bitmap: Access to which 16-bit I/O ports triggers VM exit.
MSR bitmaps: Similar to control register masks, each MSR register has a set of "read" bitmap masks and a set of "write" bitmap masks.
Every time VM exit occurs, the hardware automatically stores rich information in VMCS to facilitate the types and causes of VMM screening events. When VM entry is entered, VMM can easily inject events (interrupts and exceptions) into Guest OS because VMCS has the address of Guest OS's interrupt description table (IDT), so hardware can automatically call Guest OS's handler.
With the advent of hardware-assisted technology, the execution of VMM and Guest OS is automatically isolated through hardware. Any key event can automatically transfer the system control right to VMM. Therefore, VMM can completely control all resources of the system.
Guest OS not only runs at the highest privilege level it expects, so problems with privilege-level compression and privilege level names are solved, and system calls in Guest OS do not trigger VM exit.
The hardware uses physical addresses to access the virtual machine control block (VMCS), and VMCS saves the respective IDTR and CR3 registers of the VMM and Guest OS, so the VMM can have a separate address space, Guest OS can fully control its own address space, address space compression The problem does not exist either.
The problems of interruption and abnormal virtualization have also been well solved. The VMM simply sets the virtual interrupts or exceptions that need to be forwarded. When the VM entry is entered, the hardware automatically invokes the Guest OS interrupt and exception handlers, greatly simplifying the VMM design. At the same time, Guest OS's masking and release of interrupts may not trigger VM exit, thereby improving performance. Moreover, the VMM can also set the VM exit to be triggered when the guest OS unmasks an interrupt, so it can forward accumulated virtual interrupts and exceptions in time.
CPU hardware-assisted virtualization is in turn divided into the first and second generations. The second generation has added MMU (memory management unit) virtualization, that is, Intel EPT and AMD RVI. If you are interested, you can log in to
VMware, Citrix, Intel and AMD websites for more detailed and relevant information.
With the CPU hardware support virtualization technology, the biggest benefit is that it does not need the previous BinaryTranslation or ParaVirtualization operations, virtualization vendors no longer have to bother to find a solution here, and the performance of the full virtualization vendors catches up with paravirtualization. Vendors, para-virtualization vendors can also support operating systems that do not modify the kernel (for example, Windows or the vast majority of Linux).
CPU virtualization can be said to be the most critical core of computing virtualization, figure out VM Exit and VM Entry. Subsequent I/O virtualization and memory virtualization are built on this foundation.
Zoolied provides prime, test and dummy Silicon Wafers in diameters from 8 inch to 12 inch. Thickness 725um or 775um.
Type/Dopant: P or N,Orientation: <100> <110><111>
Front Surface: Polished , Back Surface: Polished or not polished
Contact our Zoolied Team today for any information you need about silicon wafers. Prime and test and dummy grade silicon wafers are available.
8~12 Inch Silicon Wafers,200Mm Silicon Wafers,Fz Semiconductor Silicon Wafer,Sensor Semiconductor Si Wafer
Zoolied Inc. , https://www.zoolied.com