The theoretical basis of the content-based information recommendation method mainly comes from information retrieval and information filtering. The so-called content-based recommendation method is to recommend the recommendation item that the user has not contacted based on the user's past browsing history. Mainly from two methods to describe the content-based recommendation methods: heuristic methods and model-based methods. The heuristic method is to define the relevant calculation formula based on experience, and then validate the formula based on the results of the calculation and the actual results, and then continuously modify the formula to achieve the ultimate goal. The method for the model is based on the previous data as a data set, and then learn a model based on this data set. The heuristic method used in the general recommendation system is to use the tf-idf method to calculate, and then there are tf-idf methods to calculate the keyword with higher weight in the document as the description of user characteristics, and use these The keyword is used as a vector describing the user's features; then the keyword with the highest weight in the recommended item is used as the attribute feature of the recommendation item, and then the two vectors are the most similar (the highest score is calculated with the user's feature vector). The item is recommended to the user. When calculating the similarity between the user feature vector and the feature vector of the recommended item, the cosine method is generally used to calculate the cosine value of the included angle between the two vectors.
Content-based recommendation1. Analyze data content to get a structured description of the item
2. Analyze the user's past scored or commented items as a training sample for the user
3, generate a user portrait
a. Can be the result of statistics (similarity calculation is used later)
b. It can also be a predictive model (after using class prediction calculations)
4, new items arrive, analysis of new items of goods portrait
5. Using the prediction model constructed by the user's portrait to predict whether it should be recommended to the user U
a. Strategy 1: Similarity calculation
b. Strategy 2: Classifiers make predictions
6, further, the prediction model can calculate the user's interest in new items, and then sort
7. Further, the user model is changing, and the user's portrait is updated through feedback (the user's portrait is the predictive model here)
Feedback - Learning, which constitutes a dynamic change in the user's portrait
Content-based recommendation hierarchy * Content analyzerDocument data processing
Get structured data stored in the library
* Information LearnerCollect data characteristics about user preferences, flood the data, build user characteristics information (machine learning)
Construct user interest model through historical data (by categorizing methods and extracting features, the feature is the basis for organizing user portraits)
Generate interest features (positive samples) and no interest features (negative samples)
* Filter componentsMatch user's personal information and items
Generate binary or continuous correlation judgments (cosine similarity of prototype vectors and item vectors)
Content recommendation (CB) based recommendation algorithmAt present, Collaborative Filtering Recommendations (CF) is still the most popular recommendation method at present and has been widely used in the research community and industry. However, the systems that are actually used in the industry generally do not have only the CF recommendation algorithm, and Content-based Recommendations (CB) are basically part of it.
The CB recommends products similar to the products he likes in the past based on the user's favorite items in the past. For example, a recommended restaurant system may recommend a rotisserie for him based on a user's favorite rotisserie. The earliest CB was mainly used in information retrieval systems, so many methods of information retrieval and information filtering can be used in CB.
Recommended process:The CB recommendation process generally includes the following three steps:
Item Representation: It is a characteristic project for items. In general, it expresses the attributes of items, such as item = Nongfu Spring (item: mineral water, price: 1-5, etc);
Profile Learning: Use the feature data of an item that the user (id) likes (and doesn't like) in the past to learn the user's preference profile, such as id=me, likes=(Nongfu Spring, McDonald's), doesn't like = (Betel nut, cigarette), etc.
Recommendation Generation: By comparing the characteristics of the user profiles and candidate items obtained in the previous step, this user is recommended a set of items with the most relevance.
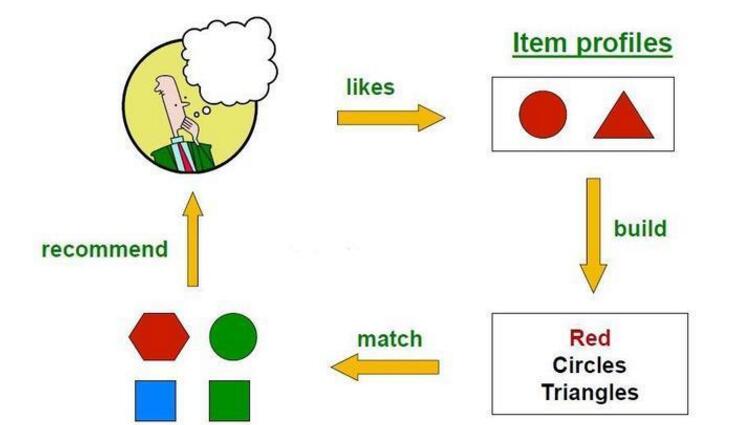
For personalized reading, an item is an article. The first step is to extract the keyword group in the article to represent the topic of the article. For example, TF-IDF can find the weight of the word in the article, for example, in the python article. In "python" is the main word mentioned, then the word is a keyword, using this method, we can vectorize the article. The second step is to find the article that the user liked before, and vectorize it through the above-mentioned TF-IDF method, and then average it to represent the article that the user generally likes. If the user likes the python language, then the user's profile ['python'] has a larger weight. The third step is to match all the items obtained in the above two steps with the profile of the user. The calculation method generally uses cosine similarity.
Detailed process1.Item Representation
Item will generally have some attributes that describe it. These properties can generally be divided into two kinds: structured and unstructured properties. The so-called structured attributes are attributes that can be quantified and can be used directly, such as people having gender, education, and geographical attributes. Non-structured attributes are attributes that need to be re-parsed and cannot be used directly, such as people's purchase records, the content of an article, etc. Unstructured data such as articles can be represented vectorized by using algorithms such as TF-IDF and word2vec.
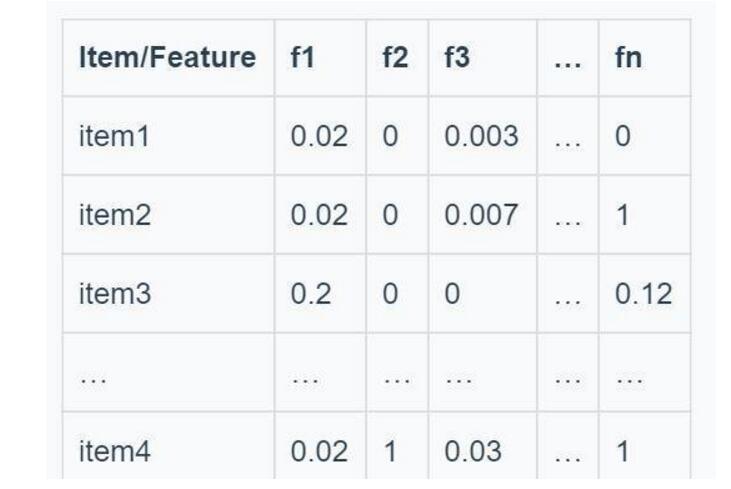
If TF-IDF is used to represent the weight of the article's corresponding keywords, the following matrix can be obtained:
2.Profile Learning
Suppose the user (id) has made a favorite judgment on some items, and made a disliking judgment on another part of the item, and these items we already have a corresponding vectorized representation, then this is the user's profile, how simple Calculate the user's profile? The formula is as follows:
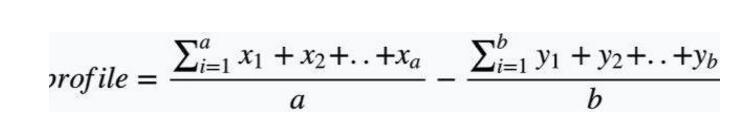
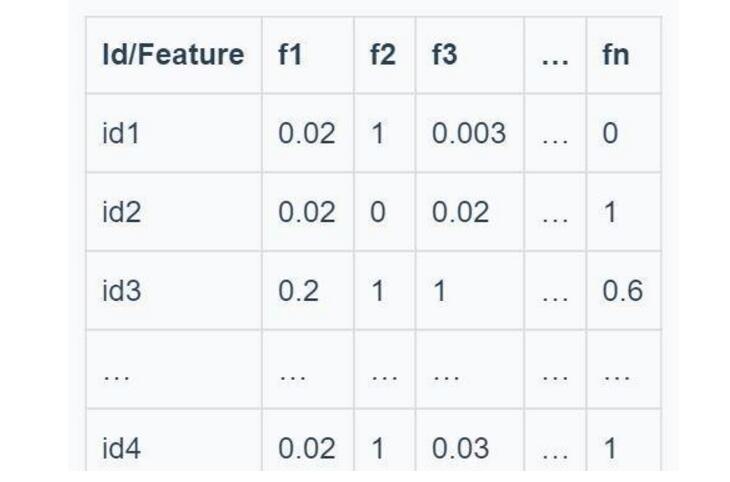
Where x is the user's favorite item, a is the total number of like items, y is the item that the user does not like, and b is the total number of items that do not like. At this time, we get another user matrix: (Of course, this is not collaborative filtering, and it is not necessary to list all users into matrix items. Actually, a single user ID can be used)
3.Recommendation Generation
Through the above two steps of all the items and all the user's profile, then to a user's profile and all the items to match, this time we generally use the cosine similarity calculation. The cosine similarity is calculated as follows. Assume that the coordinates of the vectors a and b are (x1, y1) and (x2, y2) respectively. then:
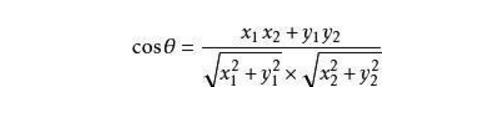
The range of the cosine value is between [-1,1]. The closer the value is to 1, the closer the two vectors are in the direction; the closer to -1, the opposite is their direction. As the above example we can calculate the following result:
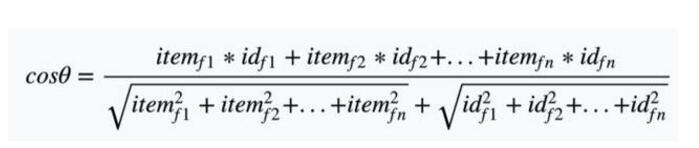
Therefore, the first N articles with the largest cosine value (the article most relevant to the user) will be recommended to the user.
Advantages and disadvantagesAdvantages: The user's personal information can be constructed using the current user evaluation; because the process is simple and interpretive, the recommendation result is easily accepted; and for the new item, no user rating is also recommended to the user.
Disadvantages: The content that can be analyzed is limited, and the novelty is poor. The new user needs the user's preference information and cannot solve the cold start problem.
Sdec 0-20Kw Diesel Generator,Sdec Soundproof Power Generator,Sdec Mobile Power Generator,Sdec Canopy Power Generator
Shanghai Kosta Electric Co., Ltd. , https://www.generatorkosta.com