As the domain of computer vision, the perception of driverlessness is inevitably the stage for CNN to play its role. This article is the eighth in an unmanned technology series that provides an in-depth introduction to CNN (Convolutional Neural Networks) for unmanned 3D sensing and object detection.
Introduction to CNNThe ConvoluTIonal Neural Network (CNN) is a deep neural network suitable for use on continuous-value input signals, such as sound, images, and video. Its history dates back to 1968, when Hubel and Wiesel discovered the directional selectivity and translational invariance of the input pattern in animal visual cortical cells, which earned them a Nobel Prize. Time advances to the 1980s. With the deepening of neural network research, the researchers found that the convolution operation on the image input and the neuron in the biological vision accept similarities in the input in the local recepTIve field, then add in the neural network. The convolution operation becomes a natural thing. The current CNN is compared to the usual deep neural network (DNN), and its features include:
A high-level neuron accepts only the input of certain low-level neurons, which are in a neighborhood in two-dimensional space, usually a rectangle. This feature is inspired by the concept of the recepTIve field in biological neural networks.
The input weights of different neurons in the same layer are shared. This feature can be considered to utilize the translation invariance in the visual input, not only greatly reducing the number of parameters of the CNN model, but also speeding up the training.

Because CNN has a specific design for the characteristics of the visual input itself in the structure of the neural network, it is the best choice for using deep neural networks in the field of computer vision. In 2012, after CNN broke the world record of ImageNet, the image recognition competition, the field of computer vision changed dramatically. Various visual tasks abandoned the traditional methods and enabled CNN to build new models. As the domain of computer vision, the perception of driverlessness is inevitably the stage for CNN to play its role.
Unmanned binocular 3D perceptionIn the unmanned vehicle perception, 3D modeling of the surrounding environment is of paramount importance. Lidars provide high-precision 3D point clouds, but dense 3D information requires the help of a camera. Humans get a three-dimensional visual experience with two eyes, and the same reason allows the binocular camera to provide 3D information. Assuming that the distance between the two cameras is B, the offset from the point P in the space to the image formed by the two cameras is d, and the focal length of the camera is f, then we can calculate the distance from the P point to the camera as:
So in order to perceive the 3D environment to get z, you need to get d through the two images I_l and I_r of the binocular camera. The usual practice is based on local image matching:
Since the value of a single pixel may be unstable, it is necessary to use the surrounding pixels and smoothness assumption d(x, y) ≈d(x+α, y+β) (assuming both α and β are small), so the solution d is changed. Become a minimal problem:
This is a very similar problem that the opTIcal flow task wants to solve, but (Il, Ir) becomes (It, It+1), so the algorithm to be described below, both apply.
MC-CNNNow let's take a look at the Matching-Cost CNN algorithm, which uses a CNN to calculate the right matching cost of the above formula. The network structure of MC-CNN is shown in Figure 1.
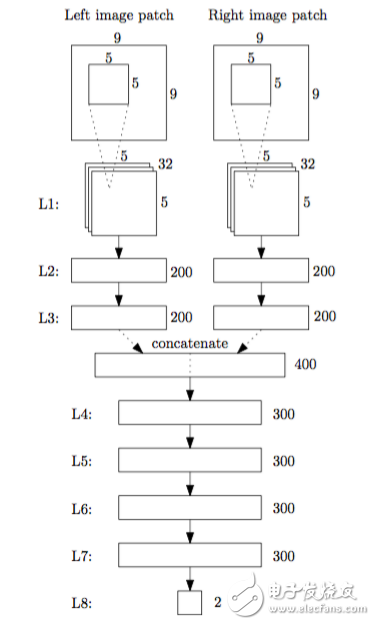
Figure 1 MC-CNN network structure
The input to this network is a small block of two pictures. The output is the probability that the two pieces do not match, which is equivalent to a cost function. When the two match, it is 0. When it does not match, the maximum is 1. This local offset estimate is obtained by searching for a possible d value for a given picture position and finding the smallest CNN output. The MC-CNN algorithm is then post-processed as follows:
Cross-based cost aggregation: The basic idea is to average the offsets of adjacent points with similar pixel values ​​to improve the stability and accuracy of the estimation.
Semi-global matching: The basic idea is that the translation of adjacent points should be similar, adding smoothing constraints and finding the optimal value of the offset.
Interpolation and image border correction: Improve accuracy and fill in gaps.
The final algorithm works as follows:

Figure 2 MC-CNN algorithm effect
Although MC-CNN uses CNN, it is limited to calculating the degree of matching. Later smoothing constraints and optimization are essential. Is it possible to use CNN in one step? FlowNet does just that.
High efficient charging speed for Toshiba laptop, stable current outlet can offer power for the laptop at the same time charge the laptop battery. The best choice for your replacement adapter. We can meet your specific requirement of the products, like label design. The plug type is US/UK/AU/EU. The material of this product is PC+ABS. All condition of our product is 100% brand new.
Our products built with input/output overvoltage protection, input/output overcurrent protection, over temperature protection, over power protection and short circuit protection. You can send more details of this product, so that we can offer best service to you!
Toshiba Adapter,Adapter For Toshiba,Power Supply For Toshiba,Laptop Charger For Toshiba
Shenzhen Waweis Technology Co., Ltd. , https://www.huaweishiadapter.com